1. 概述
Redis:Remote Dictionary Server,高性能非关系型(NoSQL)键值对数据库
Redis特性:
- key-value 存储
- 支持数据可靠性存储及落地
- 单进程但线程高性能服务器
- crash safe & recovery slow
- 单机qps可达10W
- 适合小数据量高速读写访问
1.1 应用场景
高速缓存
- 高频次,热门数据,降低数据库IO
- 分布式,做session共享
多样化数据结构
- 最新N个数据:通过List实现按时间排序的数据
- 排行榜,top N:zset有序集合
- 时效性数据,验证码:Expire过期
- 计算器,秒杀:原子性,INCR, DECR
- 大数据量去重:set集合
- 队列:list
- 发布订阅:pub/sub
1.2 安装
1 | # 1. 编译工具 |
1.3 相关知识
Redis: 单线程 + 多路 IO 复用
多路复用:使用一个线程来检查多个文件描述符 (socket) 的就绪状态,比如调用select 和pol函数,传入多个文件描述符,如果有一个文件描述符就绪,则返回,否则阻塞直到超时。得到就绪状态后,进行真正的操作可以在同一个线程里执行,也可以启动线程执行(比如线程池)
1.4 管理命令
1 | keys * |
Redis-benchmark: 服务器性能测试
1 | # 100个并发,100000次 |
1.5 优缺点
优点:
- 读写性能高
- 支持持久化,RDB & AOF
- 数据类型丰富,五种:string, list, set, sorted-set, hash
- 支持简单事务
- 支持TTL
- 支持主从复制,可以进行读写分离
缺点:
数据库容量受限物理内存(低于物理内存的60%),不能支持海量数据的高性能读写。
不具备自动容错和恢复功能
主节点宕机,可能会有部分数据未及时同步到从节点,导致数据不一致
很难在线扩容,一般在系统上线前必须保有足够的空间
buffer io造成系统OOM
2. 数据类型
2.1 基础类型
string: 字符串操作、原子计数器等
hash: 以hashmap方式存储,可用来存储json对象。
list: 消息队列,timeline等
set:Unique去重操作。统计独立IP,好友推荐去重等
sorted-set: 排行榜,TOP N操作,带权重
跳表:一种随机化的数据结构,实质就是一种可以进行二分查找的有序链表。Redis中的set类型低层使用跳表实现。
2.1.1 String
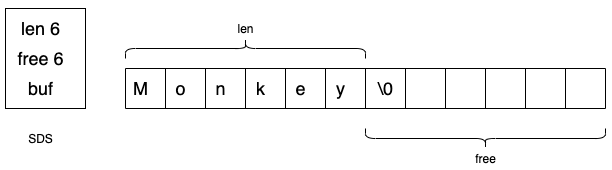
数据结构:简单动态字符串 (Simple Dynamic String, SDS),是可以修改的,内部结构类似Golang的Slice,采用预先分配冗余空间方式来减少内存的频繁分配。扩容机制,长度小于1M,按两倍扩容;超过1M,扩容一次只新增1M。最大512M
1 | get KEY |
2.1.2 List
数据结构:快速链表 quickList.
- 在元素较少的情况下,使用一块连续的内存存储,结构为ziplist,即压缩列表。
- 数据量较大时。会改成quickList,即链表存储,结构上有二外的指针prev 和 next
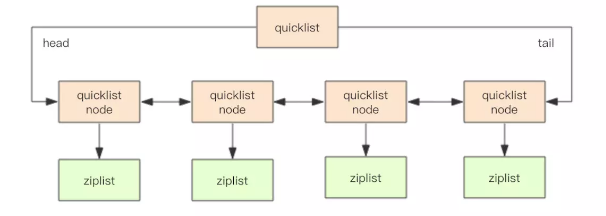
Redis 将链表和ziplist 集合起来组成quicklist,即满了快速插入删除性能,又不会出现太大的冗余空间。
1 | lpush KEY e1 e2 ... |
2.1.3 Set
数据结构:string类型的无序集合,底层其实是一个value为null的hash表,所以添加、删除和查找的时间复杂度都是o(1)
1 | sadd KEY member... |
2.1.4 Hash
数据结构:ziplist(压缩列表),hashtable(哈希表)。当field-value长度短且个数少时,使用ziplist,否则使用hashtable
1 | hset k f1 v1 f2 v2 # hmset 效果一样 |
2.1.5 ZSet
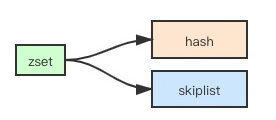
数据结构:hashtable + skiplist
- hash:关联member和score,保证member的唯一性,可直接通过member找到相应的score值
- 跳跃表:根据score值,为member排序
1 | zadd k 100 java 200 cpp 300 golang 400 python 500 php |
2.1.6 数据结构

2.1.6.1 hashTable
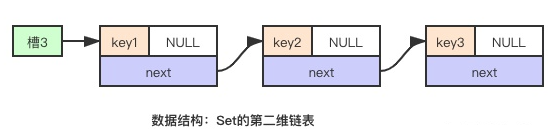
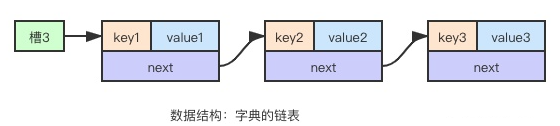
哈希表:由数组 + 链表构成的二维数据结构,数组是第一维,链表是第二维。数组中的每个元素称为槽或者桶,存储着链表的第一个元素的指针。
整体结构图:
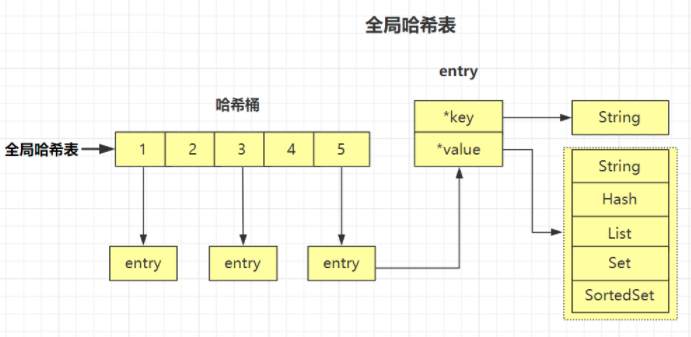
一维数组:
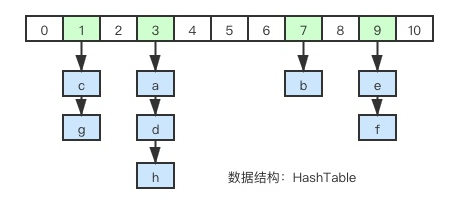
二维链表:
扩容和缩容:
- 扩容:元素个数等于一维数组长度时,会对数组进行两倍扩容
- 缩容:元素个数小于一维数组的10%
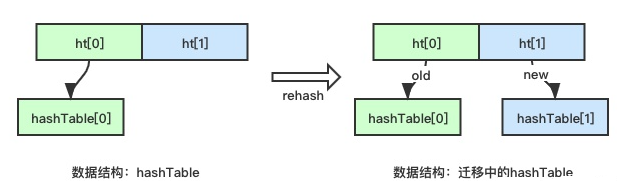
扩缩容时,需要重新申请一维数组,并对所有元素重新hash并挂载到元素链表。Redis采用rehash策略:所有的字典结构内部首层时一个数组,数组的两个元素分别指向一个hashtable,正常情况下只有一个hashtable,而在迁移过程中,保留新旧两个hashtable,元素可能会在两个表中任意一个中,因此同时尝试从两个hashtable中查找数据。当数据搬迁完毕,旧的hashtable会被自动删除。
哈希函数:将key值打散的越均匀越好,高随机性的元素分布能够提升整体的查找效率。Redis的hash函数为siphash。hash函数打散效率如果很差或有迹可循,就会存在hash攻击,攻击者利用模式偏向性产生大量数据,并将这些数据挂载在同一个链表上,这种不均匀会导致查找性能急剧下降,同时浪费大量内存空间,导致Redis性能低下
2.1.6.2 跳跃表
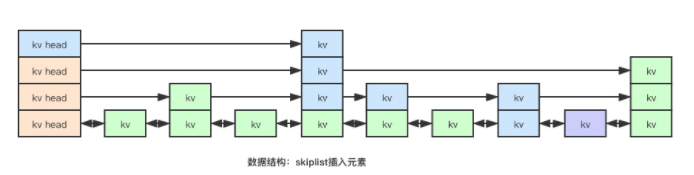
根据score值插入紫色kv节点,首先从 kv-head 的最高层启动,判断指针的下一个元素的score值是否小于新元素的score,小于则继续向前遍历,否则从kv-head降一层,重新比较
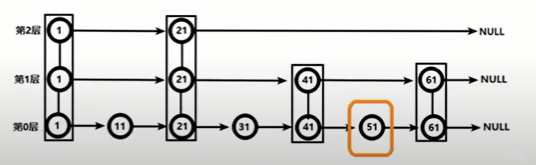
寻找51:
- 从第2层开始,1节点比51小,向后比较、
- 21节点比51小,继续向后,但后面是NULL,则从21节点下降到第1层
- 41节点比51小,继续向后,61节点比51大,则从41节点下降到第0层
- 51节点即为所要查找的节点,共查找了四次
2.2 发布订阅
1 | # 1. 订阅 |
2.3 新类型
2.3.1 Bitmaps
Bitmaps本身不是数据类型,实际它就是字符串,但可可以对字符串的位进行操作
注意:初始化bitmaps时,如果offset过大,整个初始化过程会较慢,可能会造成redis的阻塞
1 | setbit permission 2 1 |
2.3.2 HyperLogLog (基数统计)
网站统计PV(PageView): 可使用 incr, incrby实现
但独立访客UV(UniqueVistor)、独立IP、搜索记录数等需要去重和计数的问题。
HyperLogLog 用来做基数统计,其优点是,在输入元素的数量或者体积非常大时,计算基数需要的空间是固定的,并且很小。
每个 HyperLogLog 键只需要花费 12KB内存,就可以计算接近 2^64个不同元素的基数。
HyperLogLog 只会根据输入的元素来计算基数,但不会存储输入元素,所以它不能像集合一样,返回输入的各个元素。
1 | pfadd lang1 java |
2.3.3 Geospatial
Geospatial 是一个2维坐标,即经纬度。
1 | geoadd cities 121.47 31.23 Shanghai |
3. 事务和锁
3.1 事务
Redis事务:是一个单独的隔离操作。事务中所有命令都会序列化,按顺序执行;在执行过程中,不会被其他客户端发送的命令请求打断。
作用:串行执行多个命令,防止其他命令插队
Redis事务特性:
- 单独的隔离操作,一次性、顺序性、排他性的执行一个队列中的一系列命令
- 没有隔离级别
- 不保证原子性
相关命令:
- Multi: 组队阶段
- Exec:执行阶段
- Discard: 放弃执行
Queued失败,无法执行:
1 | > MULTI |
Queued成功,正常执行,跳过失败命令:
1 | > MULTI |
3.2 锁
- 悲观锁:每次操作,都上锁,别人不能操作,等我释放锁后,才能操作。MySQL中的行锁、表锁;读锁、写锁即为该类锁。
- 乐观锁:使用版本机制,在操作前,所有人均能获得当前的版本,在提交操作时,比对用户用户操作的版本是否和当前系统中的版本一致,只有在一致的情况下,操作才能成功,并生成新的版本号。乐观锁适用于多读的的应用类型,这样可提高吞吐量。
Redis使用乐观锁,CAS: check-and-set 机制实现事务。
1 | > set balance 10000 |
3.3 Lua
Redis 的乐观锁,在多写的情况下,复杂的事务操作提交失败,导致与预想不一致的情况发生
Lua脚本,很容易被 C/C++调用,也可反过来调用C/C++函数。解释器不超过200k,适合做嵌入式脚本语言。
在Redis中,可将复杂、多步调用操作,写为一个Lua脚本,一次提交给Redis执行,减少连接Redis的次数,提升性能。
1 | local uid=KEYS[1]; |
相关命令:
- EVAL
- EVALSHA
- SCRIPT LOAD - SCRIPT EXISTS
- SCRIPT FLUSH
- SCRIPT KILL
1 | EVAL script numkeys key [key …] arg [arg …] |
4. 持久化
4.1 RDB (Redis Database)
将数据以快照(snapshot)形式保存在磁盘上 (dump.db)
触发数据快照的三种机制:
save: 手动持久化,将阻塞服务器,save期间,不能处理其他命令,直到持久化完毕
bgsave: 后台异步进行快照操作。它会fork一个子进程负责处理
自动触发:
1 | save 3600 1 # 1h内,至少有一个key变化,触发持久化 |
快照保存过程:
- redis调用fork,产生一个子进程
- 父进程继续处理client请求,子进程负责将fork时刻整个内存数据库快照写入临时文件。
- 子进程完成写入临时文件后,用临时文件替换原来的快照文件,然后子进程退出。
问题:每次快照持久化都是将内存数据完整写入到磁盘,如果数据量较大,读写操作较多,必然会引起磁盘IO问题。
优势:
- RDB文件紧凑,全量备份,适合用于进行备份和灾难恢复
- 生成RDB时,Redis主进程fork一个子进程来处理保存工作,主进程不需要进行任何磁盘IO操作
- RDB恢复比AOF快
劣势:RDB数据保存子进程可能来不及保存数据,导致数据丢失
4.2 AOF (append only file)
- 以日志形式记录每个写操作(增量保存),追加写,不修改原有记录
- aof的问题:aof文件会越来越大。可通过bgrewriteaof命令,将内存中的数据以命令方式保存到临时文件,同时fork一个子进程来重写aof文件,最后替换原来的文件。
- AOF和RDB同时开启,系统默认取AOF的数据
1 | appendonly yes |
优势:
- 数据不容易丢失
- 日志文件过大时,会出现后台重写,不会影响客户端读写
- 日志文件以命令可读方式记录,容易查找命令记录来恢复数据
劣势:
- AOF日志文件比RDB文件大
- AOF开启后,写的QPS会降低
重写压缩:
AOF文件持续增长过大时,会fork一个新的进程来重新日志文件。Redis4.0后的重写,就是把rdb快照,以二进制附加在新的aof头部,替换已有的历史数据。
4.3 方案选择
Snapchat性能更高,但可能会引起一定程度的数据丢失
建议:
- 更新频繁,一致性要求较高,AOF策略为主
- 更新不频繁,可以容忍少量数据丢失或错误,Snapshot为主
5. 分布式锁
1 | setnx lock 1 |
锁释放问题:别人可以去释放你加的锁,你也亦然。
解决方案:
UUID:锁的值设置为uuid,只在获取到的锁的值等于你设置的uid时,才允许释放锁
Lua脚本:
1
2
3
4
5if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1]);
else
return 0;
end
6. 过期策略
6.1 过期键删除策略
- 定时过期:过期立即删除。对内存友好,但会占用大量CPU资源去处理过期的键,影响缓存的响应时间和吞吐量
- 惰性过期:只有当访问一个key时,才会判断它是否过期,过期则清除。对内存不友好,无用key占用了大量内存。
- 定期过期:每隔一定时间,扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。
Redis 同时使用 惰性过期 和 定期过期 两种策略。
6.2 设置和取消过期
EXPIRE
PERSIST
6.3 过期机制
1 | redis-cli |
过期机制:redis采用 Lazy Expriation 方式,即在访问key时判断是否过期,如果过期,则进行过期处理。其次,每秒对volation keys进行抽样测试,如果有过期键,那对所有过期key处理。
7. 内存淘汰策略
MySQL中2000w数据,redis中只存20w数据,如何保证redis中的数据都是热数据?
- 全局键空间选择性移除:
- noeviction:内存不足,写入新数据,报错
- allkeys-lru:内存不足,写入新数据,将移除最近最少使用的key (最常用)
- allkeys-random: 内存不足,写入新数据,将随机删除一个key
- 带TTL的键空间选择性移除:
- volatile-lru:内存不足,写入新数据,在设置了过期时间的键空间中,移除最近最少使用的key
- volatile-random:内存不足,写入新数据,在设置了过期时间的键空间中,随机移除一个key
- volatile-ttl:内存不足,写入新数据,在设置了过期时间的键空间中,移除更早过期的key
8. 集群方案
8.1 主从模式
主从同步特点:
- 一个master可拥有多个slave
- master可读写,并将变化的数据sync给slave
- slave只读,接收master的sync数据
- 缺点:master只有一个,如果挂掉,无法对外提供写服务
配置 salve:
1 | replicaof 192.168.1.200 6379 |
1 | redis-cli |
8.2 Sentinel 模式
哨兵模式建立在主从模式之上
当master挂掉,sentinel会在salve中选择一个作为master,并修改它们的配置文件,其他slave节点的配置文件也会同步修改
当master恢复后,它将不再是master,而是做为slave接收新master同步数据
多sentinel配置时,形成一个sentinel小集群,sentinel之间也会自动监控
配置:
1 | sentinel monitor mymaster 192.168.1.200 6379 |
启动:
1 | /usr/local/bin/redis-sentinel /usr/local/reids/sentinel.conf |
8.3 Cluster模式
- 多个主从模式节点网络互联,数据共享
- 客户端可连接任意一个master节点进行读写
- 不支持同时处理多个key (MSET/MGET), 因为redis需要把key均匀分布在各个节点上,高并发下同时创建key-value会降低性能并导致不可预测行为
- 支持在线增加、删除节点
- Redis 集群没有使用一致性hash,而是引入额哈希槽的概念。Redis集群有16384(2^14)个哈希槽,每个key通过CRC16校验后对16384取模来决定放置在哪个槽,集群的每个节点负责一部分hash槽。
- 数据库无法选择,都在0上
配置:
1 | cluster-enabled yes |
集群命令:
1 | # 增加节点 |
9. 缓存异常
9.1 雪崩 (大量key集中过期)
场景:服务器重启或大量缓存同一时期失效时,大量的流量会冲击到数据库上,数据库会因承受不了而当机。即缓存层出现了错误,所有数据请求到达存储层,导则存储层无法响应
解决方案:
- 构建多级缓存架构:nginx缓存 + redis缓存 + 其他缓存
- 使用锁或队列:可保证问题不出现,但不适合高并发情况
- 设置过期标志更新缓存:记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程去后台更新实际key的缓存
- 将缓存失效时间分散开:可通过随机数生成随机时间,这样保证key不在同一时间内过期。
9.2 穿透 (缓存空值)
场景:用户查询某条数据,但redis中没有,即缓存未命中;继续向持久层数据库查询,还是没有,即本次查询失败。当大量查询失败时,导则持久层数据库压力过大,即为缓存穿透
解决方案:
- 缓存空值:即数据不存在,依旧设置一个默认值到缓存中,但该key的过期时间较短。简单应急方案
- 设置白名单:使用bitmaps定义一个可访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmaps中的id进行比较,如果id不存在,则不允许访问。每次访问都要查询,效率不高
- 布隆过滤器(Bloom Filter):是一个二进制向量(位图)和一系列随机映射函数(哈希函数)。布隆过滤器科研检测一个元素是否在一个集合中,其优点是空间效率和查询时间远超过一般的算法,缺点是有一定的错误识别率和删除困难。实现:将所有可能存在的数据哈希到以恶搞足够大的bitmaps中,一个一定不存在的数据会被这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。
- 实时监控:当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,设置黑名单限制访问。
9.3 击穿 (热门key过期)
场景:某个key非常热点,高并发访问它时,该key突然失效,导则高并发请求直接访问持久数据库,就像在屏障上凿了一个洞
解决方案:
预先设置热门数据:在redis高峰访问前,把一些热门数据提前存入redis中,并加大这些热门数据key的过期时长
实时调整:现场监控哪些热门数据,实时调整可以的过期时长
使用互斥锁:缓存失效时,不立即查询数据库,先获取锁setnx mutex lock,成功后,查询数据库并设置缓存,删除mutex锁。缺点:访问效率会被降低
10. Redis优化
10.1 内存管理
1 | # HashMap成员数量,小于配置,按紧凑格式存储,内存开销少,任意一个超过,就使用真实的HashMap存储,内存占用大 |
10.2 持久化
选择aof,每个实例不要超过2G
10.3 优化方向
- 进行master-slave主从同步配置,在出现服务故障时可切换
- 在master禁用数据持久化,在slave上配置数据持久化
- Memory+swap不足。此时dump会挂死,最终会导致机器挡掉。64-128GB内存, SSD硬盘。
- 当使用的Memory超过60%,会使用swap,内存碎片大
- 当达到最大内存时,会清空带过期时间的key,即使该key未过期
- redis和DB同步,先写DB,后写redis,内存写速度快
Redis使用建议:
1 | key: |
11. Lua 脚本
11.1 优点
- 减少网络开销:可以将多个请求通过脚本的形式一次发送,减少网络时延。
- 原子操作:Redis会将整个脚本作为一个整体执行,中间不会被其他请求插入。因此在脚本运行过程中无需担心会出现竞态条件,无需使用事务。
- 复用:客户端发送的脚本会永久存在redis中,这样其他客户端可以复用这一脚本,而不需要使用代码完成相同的逻辑。
11.2 常用命令
- EVAL
- EVALSHA
- SCRIPT LOAD - SCRIPT EXISTS
- SCRIPT FLUSH
- SCRIPT KILL
11.2.1 EVAL
1 | EVAL script numkeys key [key …] arg [arg …] |
示例:
1 | 127.0.0.1:6379> eval "return KEYS[1]" 2 key1 key2 |
11.2.2 SCRIPT LOAD & EVALSHA
SCRIPT LOAD script: 不会执行脚本,而是将其进行 SHA1 求校验值,并将其永久存储在服务器脚本缓存中。
EVALSHA sha1sum :任何客户端,都可的调用该命令,来执行上面的脚本。
1 | 127.0.0.1:6379> script load "redis.call('set', KEYS[1], ARGV[1]); redis.call('expire', KEYS[1], ARGV[2]); return 1" |
11.2.3 SCRIPT EXISTS
SCRIPT EXISTS sha1 [sha1 ...]: 校验给定的 sha1 对应的脚本,是否被保存在缓存中
1 | 127.0.0.1:6379> script exists cecc687421671f6065277c7801e02f5125d444f9 |
11.2.4 SCRIPT FLUSH
SCRIPT FLUSH sync|sync: 清空服务器所有的脚本缓存
11.2.5 SCRIPT KILL
杀死当前正在运行的 Lua 脚本,当且仅当这个脚本没有执行过任何写操作时,这个命令才生效。 它的主要用于终止运行时间过长的脚本,比如一个因为 BUG 而发生无限 loop 的脚本等。
如果当前正在运行的脚本已经执行过写操作,那么SCRIPT KILL,也无法将它杀死,因为这是违反 Lua 脚本的原子性执行原则的。在这种情况下,唯一可行的办法是使用SHUTDOWN NOSAVE命令,通过停止整个 Redis 进程来停止脚本的运行,并防止不完整(half-written)的信息被写入数据库中。
11.3 实例
11.3.1 CompareAndSet
1 | local key = KEYS[1] |
执行:
1 | 127.0.0.1:6379> set name jack |
11.3.2 IP 访问频率控制
1 | local visitCount = redis.call('incr', KEYS[1]) |
执行:
1 | root@k8s-master:~/redis# redis-cli --eval ./redis_LimitIPVisit.lua ip:192.168.1.10 , 10 3 |