1. 简介
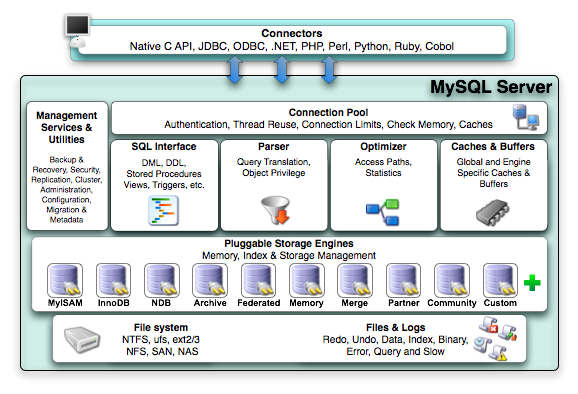
1.1 架构图
1.2 SQL 执行流程
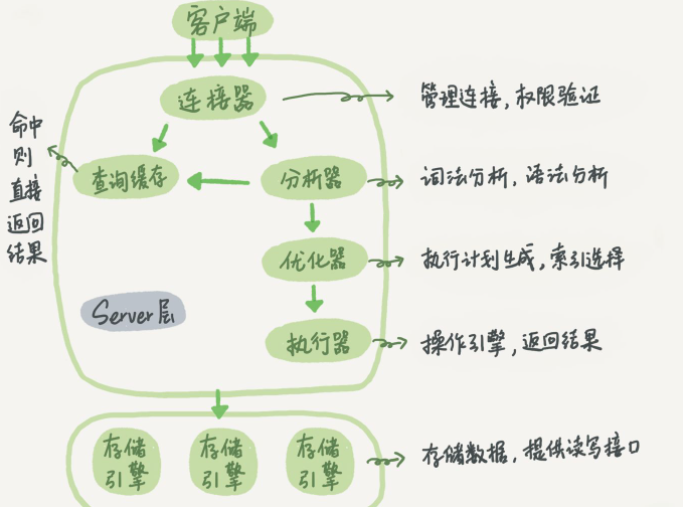
连接器: 处理客户端的连接、获取用户权限、维持和管理连接
查询缓存: 连接器拿到查询SQL后,先通过key-value方式查询缓存,如果缓存存在则直接返回。但是,它非常容易失效,只要表进行了更新,该表相关的所有查询缓存都会被清空。MySQL 8.0 已删除该功能
1 | SELECT @@query_cache_type; |
分析器:
词法分析 (识别关键字,操作,表名,列名)
语法分析 (判断是否符合语法)
优化器: 决定使用哪个索引;有多表关联时,决定表的连接顺序。最后输出执行方案
执行器: 执行SQL时,先判断用户是否对表有查询权限。如果没有,返回没有权限的错误。如果有权限,执行语句扫描表中的数据
1.3 数据类型
- DECIMAL:高精度。float/double 浮点数近似值
- CHAR:定长,存取效率高;VARCHAR变长,节约磁盘空间。
- VARCHAR(50)和VARCHAR(200): 存储相同字符串,所占空间相同,但后者在排序时会消耗更多内存,因为order by采取fixed_length计算col长度。
- INT(10): 10表示数据的长度,不是存储数据的大小。
- CHAR(10): 10位固定字符串,不足补空格
- VARCHAR(10): 10位可变字符串,不补空格
- TEXT/BLOB:尽量避免使用,查询时会使用临时表,导致严重性能开销
- TIMESTAMP:比 datetime 空间效率高
2. 引擎
| MyISAM | InnoDB | |
|---|---|---|
| 存储结构 | 每张表三个文件:表结构(.frm),表数据(.MYD),表索引(.MYI) | 所有表存储在一个或多个文件中,甚至独立的表空间文件中。 |
| 存储空间 | 可被压缩,存储空间减小 | 需要更多的内存和存储,会在内存中建立其专用的缓冲池用于高速缓冲数据和索引 |
| 备份恢复 | 通过拷贝表相关的三个文件即可 | 拷贝数据文件、备份binlog,或使用mysqldump。 |
| 文件格式 | 数据和索引分开存储 .MYD & .MYI |
数据和索引集中存储 .idb |
| 存储顺序 | 按记录插入顺序保存 | 按主键大小有序插入 |
| 外键 | 不支持 | 支持 |
| 事务 | 不支持 | 支持 |
| 锁 | 表锁,不适合高并发 | 表锁、行锁,适合高并发 |
| SELECT | MyIASM 更优 | |
| I & U & D | InnoDB 更优 | |
| 索引实现方式 | B+树,堆表 | B+树,索引组织表 |
| 哈希索引 | 不支持 | 支持 |
| 全文索引 | 支持 | 不支持 |
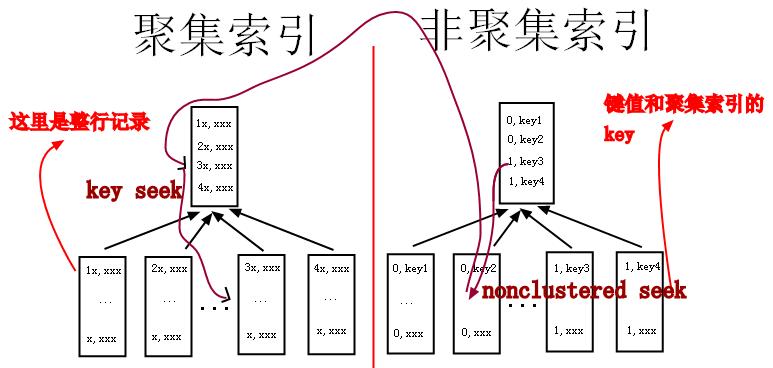
2.1 聚簇索引
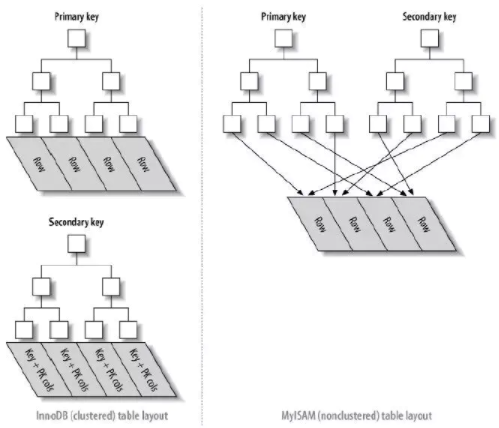
聚簇索引:叶节点存储了行数据、主键及其他索引的列数据。主键索引、覆盖索引都非常高效。
非聚簇索引:叶节点只存储了行数据地址,需要再次寻址才能得到数据
InnoDB: 主键使用聚簇索引
MyISAM: 主键和普通索引,都是非聚合索引
聚簇索引优点:数据检索高效
聚簇索引缺点:
- 插入速度严重依赖插入顺序
- 更新主键代价很高,会导致被更新行移动
- 二级索引访问需要两次索引查找,第一次找主键,第二次根据主键找到数据
2.2 InnoDB
支持事务、行锁、外键约束,MyISAM均不支持。
InnoDB 的四大特性:
- 插入缓冲 (insert buffer)
- 二次写 (double write)
- 自适应哈希索引 (ahi)
- 预读 (read ahead)
3. 索引
3.1 什么是索引
索引是一种特殊的文件,它采用排序的数据结构,保存表中记录的引用指针。能实现快速检索表数据。底层实现为B树及B+树。
索引原理:
- 把创建了索引的列进行排序
- 把排序结果生成倒排表
- 在倒排表内容上拼上数据地址链
- 查询时,先拿到倒排表内容,再取出地址链,从而拿到具体数据
索引的优缺点:
- 优点:提高了数据的检索速度
- 缺点:
- 时间方面:创建和维护索引,到要消耗时间。对表数据进行写操作,索引也要进行维护,从而降低了执行效率
- 空间方面:需要占用额外的磁盘
使用场景:
- where
- order by, group by
- join
覆盖索引:select 的字段,都建立了索引,此时将直接从索引表返回数据,不需要再次扫描数据表。索引覆盖能够很大的提高查询效率。
3.2 数据结构
3.2.1 BTree & B+Tree
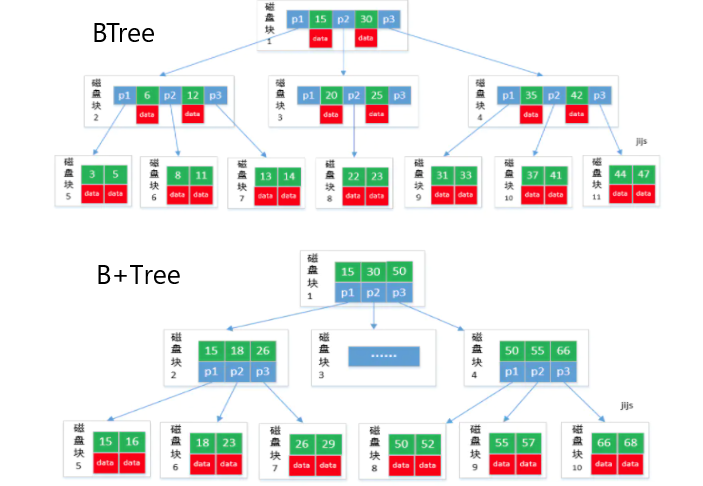
| BTree | B+Tree |
|---|---|
| 所有节点都有数据指针 | 只有叶子节点有数据指针 |
| key可能不在叶子节点上,因此搜索需要更多时间 | key都在叶子节点上,因此搜索更快,更准 |
| 树中没有key的重复项 | key重复,所有节点都在叶子上 |
| 插入会耗费更多时间 | 插入容易 |
| 内部节点删除非常复杂,树需要进行大量转换 | 删除任何节点都很容易,因为所有节点都在叶子节点上 |
| 叶子节点不存储为结构链表 | 叶子节点存储为结构链表 |
| 没有多余的搜索键 | 可能存在冗余的搜索键 |
B+树优于B树的原因:
- B+树空间利用率更高,可减少IO次数,磁盘读写代价更低。因为B+树内部节点没有指向关键字具体信息的指针,只做索引使用,内部节点相对B树小
- B+树的查询效率更加稳定。B+树所有关键字的查询路径长度相同,导致每个关键字的查询效率相当。
- B+树增删节点的效率更高。
相关树总结:
平衡二叉树:基于二分法的策略提高数据的查找速度的二叉树的数据结构;
- 每个节点最多拥有两个子节点
- Left-child < Node < Right-child
- 树的左右两边的层数相差最多一层
BTree: 平衡多路查找树,即查找路径不止两个
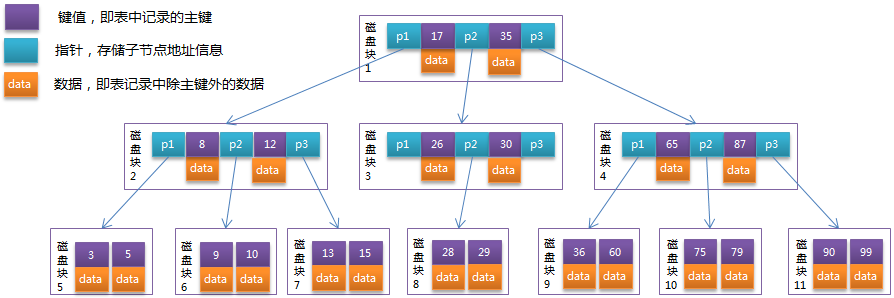
B+Tree:
- 非叶子节点:不保存关键字记录的指针,只进行数据索引
- 叶子节点:保存父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样
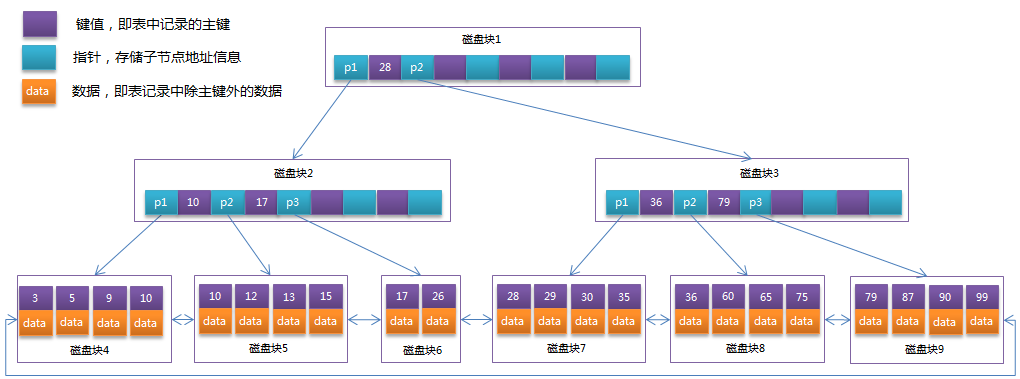
查询方式:
主键索引区:PI, 关联数据的地址,按主键查询
普通索引区:SI, 关联id的地址,然后再到达上面的地址
3.2.2 哈希索引
通过hash算法实现,常见hash算法有直接定址法、平方取中法、折叠法、除数取余法、随机数法等
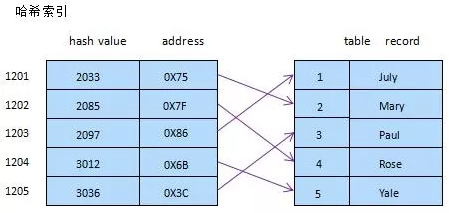
特点:
- 仅支持”=”,”IN”和”<=>”查询,不能使用范围
- 检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引
- 只有Memory存储引擎显示支持hash索引
3.2.3 全文索引
全文索引:搜索引擎使用的一种关键技术,当前 MyISAM 和 InnoDB 均支持
1 | CREATE TABLE tbl_article( |
3.3 使用原则
最左前缀匹配严重:联合索引尤为重要
较频繁的查询条件字段,应建立索引
更新频繁的字段,不适合做索引
数量大量重复的字段,不适合做索引
尽量扩展索引,不要新建索引
外键列,一定要建索引
text, blob 不能建立普通索引
NULL值字段不要创建索引,应改为NOT NULL,并设置DEFAULT
索引字段越小越好,key过长会导致间接索引层次增加,性能降低
4. 事务
事务:数据库执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。
4.1 ACID
| 特性 | 含义 |
|---|---|
| 原子性 Atomicity | 事务作为一个整体被执行,要么全部成功,要么全部失败 |
| 一致性 Consistent | 数据库无中间状态,数据库中的数据应满足完整性约束 |
| 隔离性 Isolation | 多个事务并发执行,相互不影响 |
| 持久性 Durability | 提交成功的事务,对数据库的修改是永久的,不可逆 |
4.2 隔离级别
1 | SET [SESSION | GLOBAL] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE} |
| 级别 | 含义 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| 读未提交 (Read Uncommitted) | 一个事务可以读取到另一个事务还未提交的数据 | Y | Y | Y |
| 读已提交 (Read Committed) | 事务中多次读取同一数据,都能读到其他事务提交的数据 | N | Y | Y |
| 可重复读 (Repeatable Read) | 事务中多次读取同一数据,即使其他事务提交了该是数据,该数据在本事务中不会改变。 | N | N | Y |
| 可串行化 (Serializable) | 事务串行执行,不允许并发 | N | N | N |
- 脏读:一个事务内,读取到了其他事务还没提交的数据。
- 不可重复读:一个事务内,多次读同一数据,如果另一个事务恰好修改了这个数据,那么在第一个事务中,两次读取的数据就可能不一致。
- 幻读:一个事务内,第一次查询某条记录,发现没有,但当试图更新这条不存在的记录时,竟然成功,并且再次读取同一条记录,竟然存在。
5. 锁
5.1 锁的分类
- 操作颗粒度
- 表级锁(偏读):偏向MyISAM引擎,开销少,加锁快;无死锁;锁定粒度大,锁冲突概率高,并发度低
- 行级锁(偏写):偏向InnoDB引擎,开销大,加锁慢;会产生死锁;锁定粒度小,锁冲突概率低,并发度高
- 页锁:DBD引擎,开销介于行锁和表锁之间,会出现死锁
- 操作类型:
- 读锁(共享锁): 多个读操作可同时进行而不相互影响
- 写锁(排他锁): 写操作未完成前,它会阻断其他写锁和读锁
5.2 表级锁
表读锁:
| 操作 | session 1 (lock A read) | session X |
|---|---|---|
| 读A表 | YES | YES |
| 写A表 | NO | NO |
| 读写B表 | NO | YES |
表写锁:
| 操作 | session 1 (lock A write) | session X |
|---|---|---|
| 读A表 | YES | NO |
| 写A表 | YES | NO |
| 读写B表 | NO | YES |
总结:读锁阻塞写,但不会阻塞读;而写锁会把读和写都阻塞。
1 | # 查看是否已加锁 in_use=1 |
5.3 行级锁
行锁算法:
- Record lock: 单行记录上的锁
- Gap lock: 间隙锁,锁定一个范围,不包括记录本身
- Next-key lock: record+gap 锁定一个范围,包含记录本身
5.3.1 行锁
1 | create table tbl_emp ( |
5.3.2 间隙锁:
当用范围作为检索条件时,InnoDB会将整个范围锁定,即使该范围内有不存在的记录。这些不存在的记录即为间隙(gap)
1 | create table tbl_gap( |
5.3.3 锁定一行
如何锁定一行:
1 | begin; |
select ... for update ...where ...的锁行为:
使用了索引,为行锁
未使用索引,为表锁
未查到数据,无锁
5.3.4 行锁总结
- 尽可能让所有数据检索通过索引来完成,避免无索引升级为表锁
- 尽可能减少检索条件,避免间隙锁
5.4 死锁
死锁: 两个或多个事务在同一资源上相互占用,并请求锁定对方的资源,从而导致恶性循环的现象。
解决死锁:
1)如果不同程序会并发存取多个表,尽量约定以相同的顺序访问表,可大大降低死锁机会。
2)同一事务中,尽可能做的一次锁定所需的所有资源,减少死锁产生的概率。
3)对非常容易产生死锁的业务,可尝试使用升级锁定颗粒度,通过表级锁来减少死锁发生的概率。
5.5 MVVC
- 悲观锁:想办法避免冲突。每次去拿数据时,都认为别人会修改,所以每次在拿数据时都上锁。
- 乐观锁:允许冲突,但发生冲突时,有能力解决。乐观的认为冲突不会发生,除非检测到确实产生了冲突
- 逻辑时钟 (Logical Clock)
- MVCC:Multi-version Concurrent Control
实现乐观锁:
2
3
4
5
6
7
8
UPDATE ... SET data = new_data, version = new_version WHERE version = old_version;
if (updated_row > 0) {
// 乐观锁获取成功,操作完成
} else {
// 乐观锁获取失败,回滚并重试
}
MVCC 中的版本一般选择使用时间戳或者事务ID来标识。在处理一个写请求时,MVCC不是简单的有新值覆盖旧值,而是为这一项添加一个新版本数据。在读取一个数据项时,要先确定读取的版本,然后根据版本找到对应的数据。MVCC中的读操作永远不会被阻塞。
MVCC两种读形式:
快照读:读取的只是当前事务的可见版本,不用加锁。
select * from tablename where id=xxx即为快照读当前读:读取当前版本,比如特殊的读操作,更新/插入/删除操作
1
2
3
4
5
6select * from tablename where id=xxx lock in share mode;
select * from tablename where id=xxx for update;
update tablename set ...
insert into tablename(xxx,) values(xxx,)
delete from tablename where id=xxx;
6. 视图
视图:本质上是一种虚拟表,在物理上不存在,其内容和真实的表相似。它的行和列来自定义视图的查询所引用基本表,在具体引用视图时动态生成。
6.1 特点
视图是由一个或多个实表产生的虚表
视图的建立和删除不影响基本表
对视图内容的更新(增删改)直接影响基本表
当视图来自多个基本表时,不允许添加和删除数据
6.2 使用场景
视图的用途:优化SQL查询,提高开发效率
- 重用SQL语句
- 简化复杂的SQL操作。编写完查询后,可方便重用而不必关心查询细节
- 使用表的组成部分而不是整表
- 保护数据。可给用户授予表的部分数据访问权限而不是整个表
- 改变数据格式和表示。
6.3 优缺点
优点:
- 查询简单化
- 数据安全性
- 逻辑数据独立性。视图对重构数据库提供了一定程度的逻辑独立性
缺点:
- 性能。如果视图由一个复杂的多表查询定义,那么即使视图的一个简单查询,也需要花费一定的时间
- 修改限制。较复杂的视图,可能是不可修改的
7. 存储过程
存储过程:一个预编译的SQL语句,允许模块化设计,即只要创建一次,后续可多次调用。
优点:
- 预编译的,执行效率高
- 存储过程代码直接放数据库,通过存储过程名称调用,减少网络通信
- 安全性高,执行存储过程需要一定的权限
- 可重复使用
缺点:
- 调试麻烦
- 移植困难
- 带引用关系的对象发生改变,受影响的存储过程、包将需要重新编译
- 维护困难。对于大型项目,多版本迭代的数据结构变化,存储过程维护会相当麻烦。
存储过程实例:
设置参数log_bin_trust_function_creators
1
2
3--创建函数,可能出错: This function has none of DETERMINISTIC...
show variables like 'log_bin_trust_function_creators';
set global log_bin_trust_function_creators=1;创建函数,随机产生数据
1
2
3
4
5
6
7
8
9
10
11
12DELIMITER $$
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars VARCHAR(100) DEFAULT 'abcdefghijk...LMNOPQRSTUVWXYZ';
DECLARE ret VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET ret = CONCAT(ret, SUBSTRING(chars, FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN ret;
END$$创建存储过程
1
2
3
4
5
6
7
8
9
10
11
12DELIMITER $$
CREATE PROCEDURE insert_emp(IN start INT(10), IN offset INT(10))
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit=0; #
REPEAT
SET i = i + 1;
INSERT INTO emp(name, ...) VALUES(rand_string(4), ...);
UNTIL i = offset
END REPEAT;
COMMIT;
END$$调用存储过程
1
DELIMITER ;CALL insert_emp(100, 50);
8. 主从复制
主从复制:将主库中的DDL和DML操作通过二进制日志(BINLOG) 传输到从库上,然后在从库上重现这些操作,使主从数据库一致
主从复制的用途:
- 主数据库宕机,切到从库继续工作
- 实现读写分离
- 数据库日常备份
主从复制流程:
主:binlog线程,记录下所有改变数据的日志到binlog中
从:io线程,从master上拉取binlog日志,并放入relay log中
从:sql执行线程,执行relay log中的语句
8.1 读写分离方案
mysql-proxy优点:直接实现了读写分离和负载均衡,不用修改代码
缺点:性能低,不支持事务。不推荐使用
ORM实现
8.2 主从配置
1 | # master |
授权:
1 | # master |
9. SQL
9.1 语句分类
- DDL: CREATE, DROP, ALTER,TRUNCATE
- DQL: SELECT
- DML: INSERT, UPDATE, DELETE
- DCL: GRANT, REVOKE, COMMIT, ROLLBACK
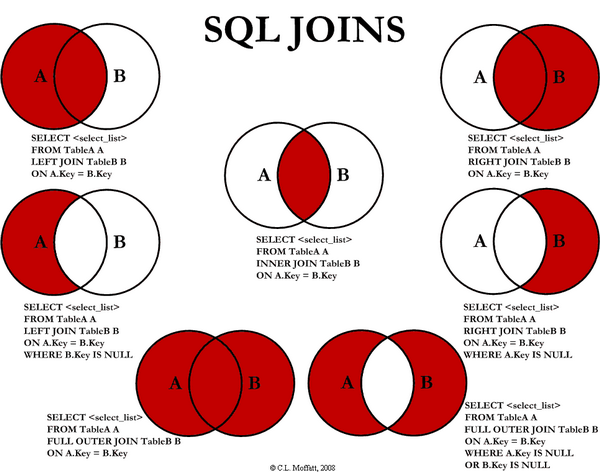
9.2 关联查询
INNER JOIN
LEFT JOIN:以左表为主,先查出左表,然后按照ON的关联条件匹配右表,没有匹配到用NULL填充。
RIGHT JOIN:以右表为主,先查出右表,然后按照ON的关联条件匹配左表,没有匹配到用NULL填充。
FULL OUTER JOIN :MySQL不支持,但可实现
1
2
3SELECT * FROM A LEFT JOIN B A.id=B.aid
UNION
SELECT * FROM A RIGHT JOIN B A.id=B.aid;UNION:合并多个集合(联合查询的列必须一致),相同的记录会合并
UNION ALL:不会合并重复行,效率比UNION低
9.3 子查询
- 条件:一条SQL语句的查询结果作为另一条查询语句的条件或查询结果
- 嵌套:多条SQL语句嵌套使用,内部的SQL查询语句称为子查询
子查询的三种情况:
1)子查询是一个单行单例,使用“=”
1 | select * from users where age=(select max(age) from users); |
2)子查询是一个多行单例,使用“in”
1 | select * from users where age in (select age from users where gender='female'); |
3)子查询是多行多列,结果集类似一张虚表,但不能使用where
1 | select * from dept d, (select * from users where age>20) u where u.dept_id=d.id; |
9.4 in & exists
in: 把外表和内表做hash连接
exists: 对外表做loop循环,每次loop循环再对内表进行查询
执行效率对比:
- 如果查询的两个表大小相当,in和exists差别不大
- 如果两个表中一个较小,一个较大,则子查询表大的用exists,子查询表小的on-going-in
- not exists 使用索引,但not in无法使用索引,所以not exists更高效
9.5 分页
1 | SELECT * FROM table_name LIMIT 5; // 1~5 |
9.6 查找字段相同的数据
1 | select a.id from group_member a, |
9.7 循环更新数据
1 | UPDATE contact a INNER JOIN users b ON a.inviter=b.phone SET a.inviter_id=b.id; |
9.8 强制删除外键引用的表
1 | SET FOREIGN_KEY_CHECKS = 0 |
10. 日志
10.1 undoLog
事务回滚日志
insert undo log: 插入数据时产生,事务提交后丢弃
update undo log: 更新或删除数据时产生,快照读的时候需要所以不能直接删除,只有当系统没有比这个log更早的read-view的时候才能被删除
10.2 redoLog
重做日志文件,记录数据修改之后的值,用于持久化到磁盘中
redo log buffer: 内存中的日志缓冲,易丢失
redo log file: 磁盘上的日志文件,持久化的。记录物理数据页修改的信息。当数据更新时,InnoDB会先将数据更新,然后记录redoLog在内存中,然后找个时间将redoLog持久化到磁盘。不管提交是否成功都要记录
10.3 binLog
逻辑日志,记录sql的原始逻辑
数据修改时,binlog会追加写入指定大小的物理文件中,如果文件写满则创建一个新的文件写入;用于复制和恢复在主从复制中,从库利用主库的binlog进行重播。
binlog 的三种格式:statement, row 和 mixed
statement:每一条修改数据的sql都会记录在binlog中。不需要记录每一行的变化,减少了 binlog 日志量,节约了 IO,提高性能。由于sql的执行是有上下文的,因此在保存的时候,需要保存相关的信息,同时还有一些使用了函数之类的语句无法被记录复制。
row:不记录sql语句上下文信息,仅保存那条记录被修改。记录单元为每一行的改动,基本可以全部记录下来。但由于操作过多,导致大量行改动 (如:alter table)。此种模式的文件保存信息过多,日志量太大。(新版优化:当表结构发生变化时,记录操作语言,而不是行记录)
mixed:折中方案。普通操作使用statement记录,当无法使用statement时使用row。
11. 查询分析
11.1 问题分析
- 开启慢查询日志,设置阈值,比如超过5s即为慢SQL,将其记录下来
- explain 分析慢SQL,可解决大部分问题
- show profile,查询SQL的执行细节和生命周期
- 数据库参数调优
11.2 慢查询日志
slow_query_log: 慢查询日志参数
long_query_time:慢查询SQL记录阈值,默认10s
1 | mysql> show variables like 'slow_query_log%'; |
慢SQL分析工具:mysqldumpslow
11.3 explain
11.3.1 explain 详解
1 | mysql> explain select * from tbl_emp where id=1; |
注意字段含义:
id: 优先级
- 相同时,自上而下顺序执行
- 不同时,id值越大,越早执行
select_type: 查询类型
- simple
- primary: 最外层查询,也是最后的查询
- subquery
- derived:衍生虚表
- union
- union result: 联合结果合并
table:表名称,也可以为
<derived N>或<UNION N>type: 访问类型,从好到差的顺序如下,至少需要优化到range
- system: 表中只有一条数据,相当于系统表
- const: 一次索引就能找到,即主键、唯一索引
- eq_ref: 唯一性索引扫描,只有一条数据与之匹配,常见于主键、唯一索引
- ref: 非唯一性索引扫描,可能匹配到多条数据
- range: 检索特定范围的行。使用一个索引来选择行,即
between, >, <, in - index: 全索引扫描
select id from tbl_user, 直接从索引中获取数据 - ALL: 全表扫描
select * from tbl_user
possible_keys: 可能使用到的索引,但不一定实际使用
key:
- primary: 主键索引
- idx_X: 普通索引名
- NULL:未使用索引
key_len: 索引字段最大可能长度,越小越好
ref: 索引条件使用到的值。
where uid=tbl_user.id and name='R&D'- const: 常量条件
- tbl_user.ID
- NULL
rows: 估算所查记录需要读取的行数,越小越好
Extra:
- Using filesort: 索引外排序,即无法使用索引进行排序,被称为文件排序。order by 未用到索引时出现。要想办法优化
- Using temporary: 使用临时表保存中间结果,常见于order by 或group by。较严重问题,可将by后的字段建立联合索引来解决该问题
- Using index: 使用索引。索引覆盖:查询的列,可直接从索引中得到,不必读取数据行,即查询的列被所建索引覆盖
- Using where
- Using join buffer
- impossible where: where 条件 false,
where name='jack' and name='tom' - select tables optimized away
- distinct
11.3.2 索引优化
- 尽量减少join中的NestedLoop的循环总是:永远用小结果集驱动大结果集。
- 优先优化NestedLoop的内层循环
- 保证join中被驱动表上join条件字段被建立索引
优化原则:小表驱动大表,即小表数据作为过滤条件
A为大表,B为小表,此时 in 的效率大于 exists:
1 | select * from A where b_id in (select id from B) |
A为小表,B为大表,此时 exists 的效率大于 in:
1 | select * from A exists (select 1 from B where B.id = A.b_id) |
注意:exists (sub-query) 只返回 True 或 False
11.3.3 索引失效
全值匹配最优
最佳左前缀法则
不在索引列上做任何操作(计算、函数、类型转换等),会导致全表扫描
不能使用索引中范围条件右边的列
where name='jack' and age>20 and score=90三字段索引尽量使用覆盖索引(即直接从索引中查询数据,无需扫描表)即少使用
select *使用不等于(!= 或 <>)时,无法使用索引,导致全表扫描
is null, is not null 无法使用索引
like %xxx...无法使用索引,导致全表扫描。- 解决方案:使用覆盖索引(即select 索引列),然后从索引中直接获取
字符串不加单引号索引失效
少用
or,它会导致索引失效
11.3.4 索引总结
- 带头大哥不能死
- 中间兄弟不能断,永远要符合左前缀最佳匹配原则
- 索引列上不计算
- like %加右边
- 范围之后全失效
- 字符串有引号
11.4 Show profile
用来分析当前会话中语句执行的资源消耗情况,可用于SQL的调优测量。
1 | show variables like 'profiling'; |
严重问题:
- converting HEAP to MyISAM: 查询结果太大,内存不足,使用磁盘
- creating tmp table: 拷贝数据到临时表,用完删除
- copying to tmp table on disk: 临时表存储在磁盘上,更要命
- locked:
11.5 全局查询日志
注意:绝对不能在生产环境开启此功能
1 | mysql> show variables like 'general_log%'; |
11.6 Order by
尽量使用 index 方式排序,避免使用 FileSort 方式排序
Order by使用Index的条件:
- order by 后使用索引最左前列
- Where 条件与 order by子句条件组合满足索引最左前列
提高 order by 效率:
不要用
select *, 只查询order by 后的字段:- query的字段长度总和小于max_length_for_sort_data时,排序字段不为TEXT|BLOB时,使用单路排序,否则使用多路排序(即两次磁盘扫描)
- 两种算法的数据可能超出sort_buffer容量,超出之后,会创建tmp文件进行合并排序,导致多次IO
sort_buffer_size:尝试提高该参数值,避免产生tmp文件
max_length_for_sort_data: 尝试提高该参数值会增加改进算法的效率。但如果太高,会导致磁盘IO过高,CPU使用率低的情况
排序的两种方式:filesort, index
KEY a_b_c (a, b, c)
order by 使用索引左前缀:
- ORDER BY a
- ORDER BY a, b
- ORDER BY a, b, c
- ORDER BY a DESC, b DESC, c DESC
WHERE中的索引与order by中的索引构成最左前缀:
WHERE a=const ORDER BY b, c
WHERE a=const AND b=const ORDER BY c
WHERE a=const AND b>const ORDER BY b, c
不能使用索引进行排序
- ORDER BY a ASC, B DESC, c DESC // 排序不一致
- WHERE x=const ORDER BY b, c // 丢失a索引
- WHERE a=const ORDER BY c // 丢失b索引
- WHERE a=const ORDER BY a, d // d不是索引的一部分
- WHERE a in (…) ORDER BY b, c // 范围不能使用索引
11.7 Group by
- Group by 本质上先排序后分组,遵照索引最佳左前缀原则
- 当无法使用索引时,增大max_length_for_sort_data和sort_buffer_size参数
- where 高于 having,能写在where的限定条件不要去having限定
12. SQL 性能优化
为避免全表扫描,涉及 WHERE 和 ORDER BY 的字段建立索引
避免 WHERE 中使用 NULL 判断,建表时尽量使用NOT NULL
避免 WHERE 中使用 != 或 <>,这些操作可使用索引:<, <=, =, >, >=, BETWEEN, IN,LIKE (某些时候)
避免 WHERE 中使用 OR,它会导致引擎放弃使用索引而进行全表扫描,可以使用 UNION 代替
慎用 IN 和 NOT IN,连续的数值,推荐BETWEEN
WHERE 中字段 不要使用函数、表达式
1
2SELECT * FROM record WHERE amount/30 < 1000;
SELECT * FROM record WHERE convert(char(10), date, 112) = '20201220';用EXISTS 代替 IN
1
2select num from a where num in (select num from b)
select num from a where num exists (select 1 from b)索引会提高SELECT的效率,但也降低了INSERT和UPDATE的效率(索引重建), 一个表的索引,最好不要超过6个
JOIN的表不要超过5个,考虑使用临时表。
少用子查询,视图嵌套不要超过2层
数量统计,用
count(1)代替count(*)记录是否存在,用 EXISTS 代替
count(1)>=效率比>高GROUP BY 前,先进行数据过滤:
1
2select job, avg(sal) from emp GROUP BY job HAVING job='engineer' or job='saler';
select job, avg(sal) from emp where job='engineer' or job='saler' GROUP BY job;尽量不使用触发器,trigger事件比较耗时
避免使用DISTINCT
13. 索引问题
13.1 什么是索引
索引是一种特殊的文件,InnoDB 数据库上的索引是表空间的一个组成部分,它包含了对数据表中所有记录的引用指针,所以它要占用物理空间。
索引是一种排序的数据结构,以协助夸斯查询、更新数据库中数据。索引的实现通常使用B树及B+树。
13.2 索引优缺点
优点:
- 提高检索速度
缺点:
- 创建和维护索引要消耗时间,即对表中数据进行增、删、改,索引也需要维护
- 索引需要占用物理空间
13.3 索引类型
按存储结构:
- BTree, B+Tree 索引
- Hash 索引
- full-index 全文索引
- R-Tree
按应用层次:
- 普通索引
- 唯一索引
- 符合索引
13.4 索引底层实现
Hash索引:基于hash表,只有精确匹配索引的查询才有效。对每行的索引列计算一个哈希值,并将其存储到索引表中,同时索引表中保存指向每列数据的指针。
B+Tree: 数据都住叶子节点上,并且增加了顺序访问指针,每个叶子节点都指向相邻的叶子节点的地址。相比BTree,进行范围查找只需要查找两个节点,进行遍历接口,效率更高
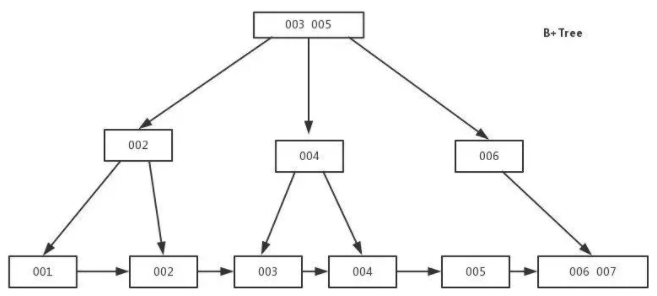
13.5 选 B+Tree,而不是BTree, Hash, 二叉树, 红黑树
BTree:
- B+树磁盘读写代价更低:B+树的内部节点并没有指向关键字具体信息的指针,因此其内部节点相对BTree更小,如果把所有同一内部节点的关键字存放放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存的需要查找的关键字也就越多,相对IO读写次数就降低了。
- B+树的数据存储在叶子节点上,分支节点均为索引:方便扫库,只需要扫一遍叶子节点接口。而B树因为其分支节点同样存储着数据,要找到具体的数据,需要进行一次中序遍历按序来扫。
Hash:
- 可快速定位,单没有排序,IO复杂度高
- 适合等值查询,不支持范围查询
- 不支持部分索引匹配查询
二叉树:树的高度不均匀,不能自平衡,查找效率和数据有关(树的高度),IO代价高
红黑树:树的高度随着数据量增加而增加,IO代价高
99. 问题集
99.1 删除百万级别数据
不要直接去操作,直接操作会存在索引更新问题;另外删除过程中断,会导致回滚
1)先删除索引
2)删除无用数据
3)重建索引
99.2 线上环境大表,添加索引
数据量超过100W,直接增加索引,可能导致服务器奔溃
两种方法:
1)临时表
注意:此方法可能会损失少量数据
1 | --复制旧表结构 |
2)主从切换
从库中进行加字段、索引
主库切换到从库
99.3 大表数据查询优化
1)优化schema、sql、索引
2)增加缓存 redis 等
3)主从复制,读写分离
4)垂直拆分(一表分多表)。根据模块耦合度,将一个大的系统拆分成多个小系统,即分布式系统
5)水平切分(存储数据分片)。大表,考虑选择合适的分片(sharding key).
分片问题:
- 事务:需要支持分布式事务
- 跨库join、count, order by, group by及聚合函数等:分别在各个节点上得到结果,然后在应用程序端进行合并。
- 数据迁移、容量规划、扩容
- ID问题:Twitter的分布式自增ID算法Snowflake
- 跨分区排序:多节点查询,结果集汇总并再排序
99.4 慢查询优化
- 分析查询语句,检查是否load了额外的数据,对查询语句重写,去除多余的查询
- 分析语句的执行计划,获取其使用索引的情况,优化索引,使其尽可能命中
- 已无法优化的大表,考虑横向或纵向分表
99.5 使用主键
主键的好处:确保数据在整张表中的唯一性。在CURD的时候能确保操作数据范围安全
推荐使用自增ID,而不是UUID。因为InnoDB中的主键索引是聚簇索引,即主键索引的B+上叶子节点上存储了主键索引及全部数据(按顺序)。使用自增ID,只需要不断想后排列即可;但如果是UUID,先确定顺序,导致数据移动等操作,使插入性能下降。
99.6 字段定义要求not null的好处
null值会占用更多的字节,也会在程序中造成很多与预期不符的情况
99.7 存储密码散列
密码散列、盐值、也会手机号等固定长度的字符串应该使用char而不是varchar,这样可以节约空间且提高检索效率。
99.8 数据库CPU飙升到500%怎么处理
1)使用top观察是不是mysqld占用导致的,如果不是,找到占用高的进程,并进行处理
2)对于mysqld造成的问题,可以使用show processlist 查看 session 情况,是否有消耗 sql 的资源在运行。查看执行计划是否准确,index是否缺失等
99.9 重复值高的字段不能建索引
未命中索引的原因:
查询的数据量可能已经是总数据量的20%以上了,这个时候就会选择表扫描。
索引坏块,需要重建索引。
原因:
1)非聚簇索引存储了对主键的引用,如果select字段不在非聚簇索引内,就需要跳到主键索引(图中从右边索引树跳到左边的索引树),再获取select字段值
2)如果非聚簇索引值重复率高,那么将查询时就会出现图中从右边跳到左边的情况,导致整个流程很慢